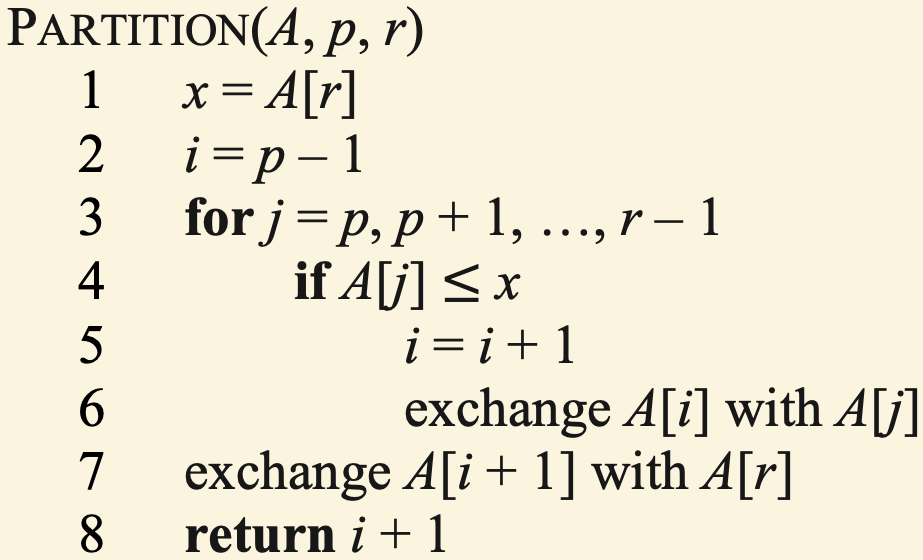Multiple-Choice Questions
Question 1: Hash Functions
Which of the following properties should a good hash function NOT possess?
- Uniformity: It should distribute the keys uniformly across the hash table.
- Randomness: It should map the same key to a different location in the hash table each time it is computed.
- Independence: It should generate the hash value of each key independently of any other key.
- Efficiency: It should require minimal time and resources to compute the hash value.
Answer 1: Hash Functions
The correct answer is II. A good hash function should deterministically map the same key to the same location in the hash table to ensure that data can be reliably retrieved.
The other properties (I, III, and IV) are desirable characteristics of a good hash function.
Question 2: Open-Address Hash Tables Using Linear Probing
How many distinct probe sequences are used in open-address hash tables with linear probing, assuming that the hash table has \(m\) slots?
- \(\lfloor m / 2 \rfloor\)
- \(m\)
- \(m^2\)
- \(m!\)
Answer 2: Open-Address Hash Tables Using Linear Probing
The correct answer is II. In open-address hash tables with linear probing, there are \(m\) distinct probe sequences, one for each slot in the hash table. Each probe sequence starts at a different initial hash index and continues linearly through the table until an empty slot is found or the key is located.
Linear probing samples only a small fraction of all \(m!\) possible probe sequences.
Question 3: Hash Table with Chaining
What is the average running time of an insertion into a hash table if chaining is used, assuming that the load factor \(\alpha\) is \(\Theta(1)\)? In the expressions below, \(n\) stands for the number of keys already in the hash table.
- \(\Theta(1)\)
- \(\Theta(\log n)\)
- \(\Theta(n)\)
- \(\Theta(n \log n)\)
Answer 3: Hash Table with Chaining
The correct answer is I because, on average, each bucket in the hash table contains \(\alpha = \Theta(1)\) keys. Although all keys in a bucket may have to be checked during insertion, the asymptotically constant average bucket size allows for \(\Theta(1)\) insertion.
Generally, the average-case time complexity for insertion in a hash table with chaining is \(\Theta(1 + \alpha)\), which simplifies to \(\Theta(1)\) when \(\alpha = \Theta(1)\).
Question 4: Searching a Red-Black Tree
What is the worst-case running time of a search for a node in a red-black tree containing \(n\) nodes?
- \(\Theta(1)\)
- \(\Theta(\log n)\)
- \(\Theta(n)\)
- \(\Theta(n \log n)\)
Answer 4: Searching a Red-Black Tree
The correct answer is II. In all binary search trees, the worst-case running time for searching a node scales as \(\Theta(h)\), where \(h\) is the height of the tree. Because the height of a red-black tree is \(\Theta(\log n)\), the worst-case running time is \(\Theta(\log n)\) for this self-balancing tree type.
Question 5: Recursive Matrix Multiplication
Consider the Matrix-Multiply-Recursive(\(A\), \(B\), \(C\), \(n\)) procedure defined on the right. Which recurrence relation correctly describes its running time \(T(n)\)?
- \(T(n) = 8T(n/2) + \Theta(n)\)
- \(T(n) = 8T(n/2) + \Theta(n^2)\)
- \(T(n) = 4T(n/2) + \Theta(n)\)
- \(T(n) = 4T(n/2) + \Theta(n^2)\)
Answer 5: Recursive Matrix Multiplication
The correct answer is II. Matrix-Multiply-Recursive divides each of the two input matrices into submatrices of size \(n/2 \times n/2\) and makes eight calls to itself. The additional work done outside the recursive calls, which involves adding the resulting submatrices together, takes \(\Theta(n^2)\) time.
According to the Master Theorem, the running time of the recurrence relation \(T(n) = 8T(n/2) + \Theta(n^2)\) is \(\Theta(n^3)\).
Exercise: Recursion Tree for Merge Sort
The running time of merge sort, applied to an array containing \(n\) numbers, follows the recurrence relation
\[\begin{equation*}
T(n) =
\begin{cases}
\Theta(1) & \text{if } n=1, \\
2T(n/2) + \Theta(n) & \text{if } n>1.
\end{cases}
\end{equation*}\]
- Sketch the recursion tree. Clearly indicate the total cost at each level, the number of levels in the recursion, and the number of leaves at the bottom of the tree.
- Derive the total running time of the algorithm in Θ-notation using either the recursion-tree method or the Master Theorem. Show your working.
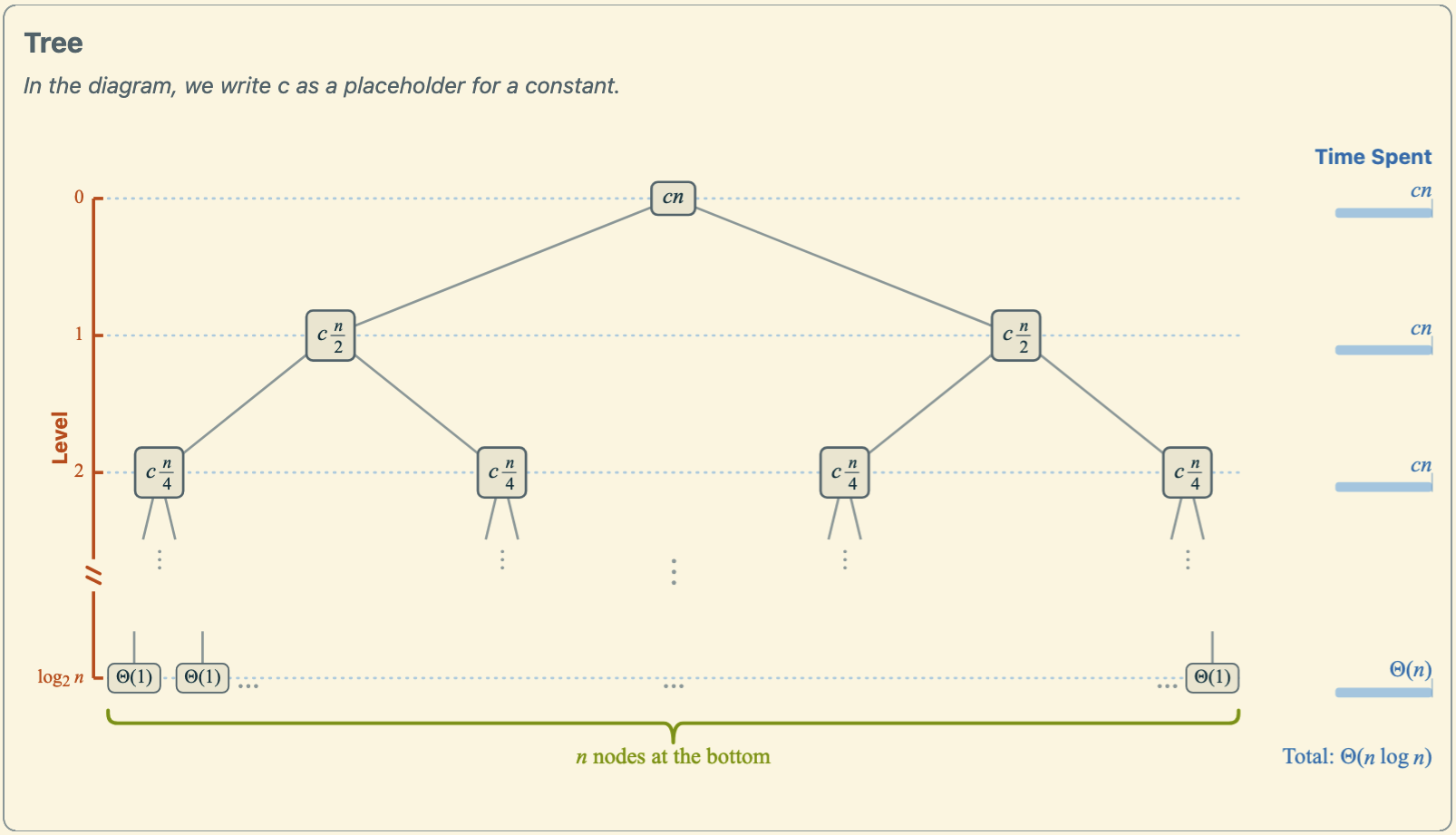
Solution, Part a: Recursion Tree for Mergesort
![]()
Solution, Part b: Derivation of Mergesort’s Running Time
In the recursion tree, each level has a total cost of \(\Theta(n)\). The number of levels in the recursion is \(\log_2 n + 1\), which can be seen from the number of times \(n\) can be divided by 2 until it reaches 1. In each of the top \(\log_2 n\) levels, the cost is \(\Theta(n)\), and the bottom level has a cost of \(\Theta(1)\) per leaf, with \(n\) leaves in total. Thus, the total cost at the bottom level is also \(\Theta(n)\). Summing the costs across all levels gives \(T(n) = \Theta(n) \cdot (\log_2 n + 1) = \Theta(n \log n)\).
Alternatively, we can derive the same result from the Master Theorem. Because \(a = 2\) and \(b = 2\), we have \(p = \log_b a = 1\). Furthermore, \(f(n) = \Theta(n) = \Theta(n^p)\). Therefore, by case 2 of the Master Theorem, we conclude that \(T(n) = \Theta(n \log n)\).
Quicksort Pseudocode
![]()
![]()
Exercise: Quicksort’s Partitioning Procedure
The figure below illustrates the steps involved in the Partition procedure, which is part of the Quicksort algorithm, applied to the input array \(\langle 5, 0, 7, 4, 8, 9, 2, 6\rangle\). You can find the pseudocode of the Partition procedure on the previous slide:
![]()
Illustrate the steps of the Partition procedure applied to \(\langle 6, 1, 2, 7, 4, 3, 5\rangle\) in a similar manner. You do not need to use colors, but indicate the locations of \(i\), \(j\), \(p\), and \(r\).
Solution: Quicksort’s Partitioning Procedure
![]()